
As a programmer or system administrator, you often need to work with large text files, log files, and configuration files. These files can be difficult to read and analyze manually. In such cases, using command-line tools like grep and sed can make the job much easier. In this blog post, we will explore how to use grep and sed to search and manipulate text in a Unix/Linux environment.
Grep
Grep stands for Global Regular Expression Print. It is a command-line tool that searches for patterns in a given text file or input. Grep uses regular expressions to match the search pattern.
Basic Syntax
The basic syntax of grep is as follows:
grep [options] pattern [file]
pattern is the regular expression you want to search for.
file is the file you want to search. If no file is provided, grep will read from standard input (stdin).
Examples
Let’s start with some basic examples:
Search for a pattern in a file:
grep "error" syslog.txt
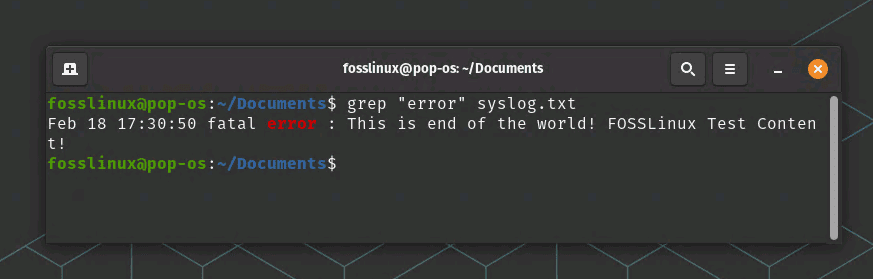
grep command – searching for string in a file example
This command will search for the string “error” in the file syslog.txt and print all the lines that contain the pattern. As you can see in the above example, the search string is highlighted in red color in Pop!_OS. The command prints the entire line having the string “error”. This is an extremely useful command when you have a system log file with thousands of lines.
Search for a pattern in multiple files:
grep "error" syslog.txt syslog_2.txt
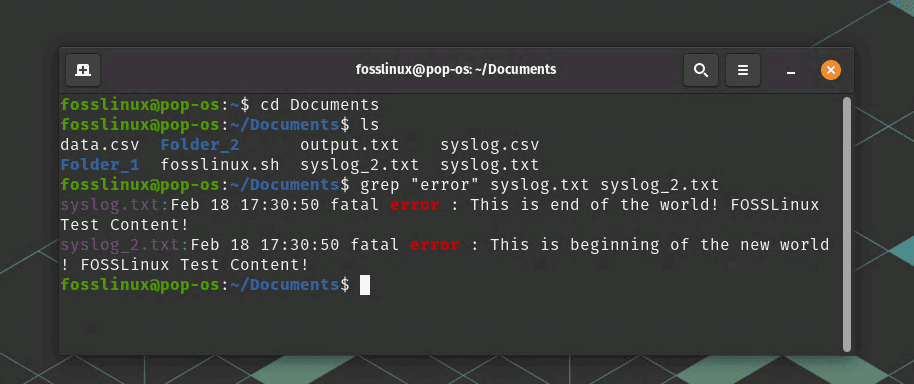
grep command usage – searching in multiple files example
This command will search for the error in both syslog.txt and syslog_2.txt.
Search for a pattern recursively in a directory:
grep -r "error" /path/to/directory
This command will search for the error in all files in the directory /path/to/directory and its subdirectories.
Options
Grep has many options that can be used to customize its behavior. Here are some commonly used options:
- -i: Ignore case when searching.
- -v: Invert the match, i.e., print all lines that do not match the pattern.
- -c: Print a count of matching lines instead of the lines themselves.
- -n: Print the line number along with the matching line.
- -w: Match the whole word only.
- -e: Search for multiple patterns.
- -f: Read the patterns to search from a file.
Examples
Ignore case when searching:
grep -i "Error" syslog.txt
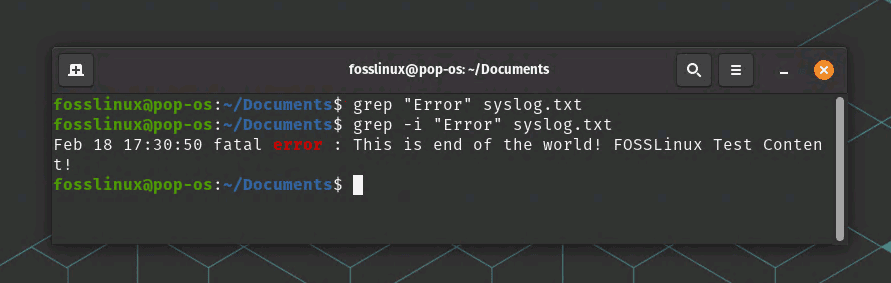
grep usage with ignore case example
This command will search for the pattern “Error” in syslog.txt regardless of case. In our example image above, the first line is searching for “Error” inside the syslog.txt and yielded zero results. But using the ignore case operator -i shows the line with the error string.
Print a count of matching lines:
grep -c "error" syslog.txt
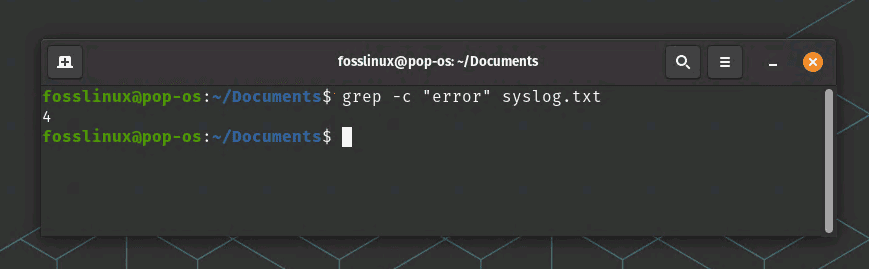
grep print number of lines example
This command will print the number of lines in syslog.txt that contain the pattern.
Print the line number along with the matching line:
grep -n "error" syslog.txt
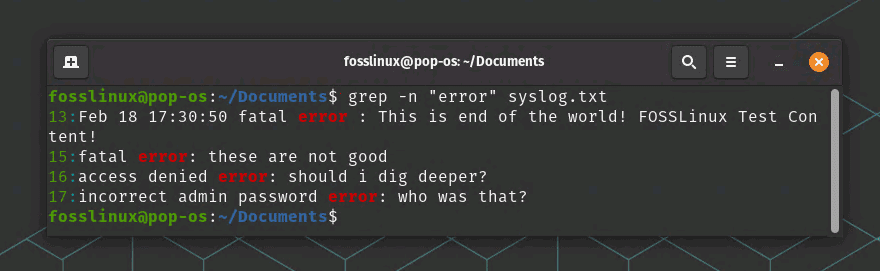
grep – print the line number along with the matching line
This command will print the line number along with each line that contains the pattern.
Match the whole word only:
grep -w "fatal error" syslog.txt

grep – match the whole word only
This command will search for the whole word “fatal error” in file.txt and not match partial words like “error”.
Search for multiple patterns:
grep -e "fatal" -e "error" syslog.txt
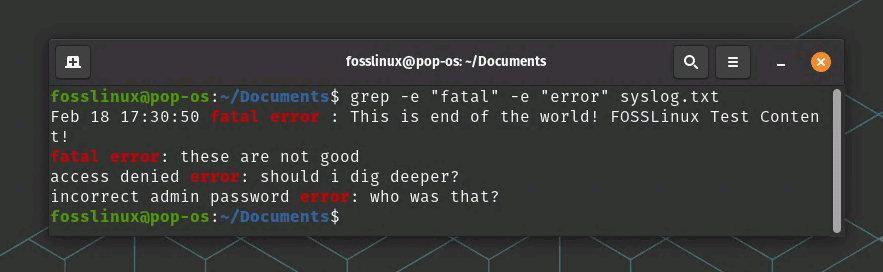
grep – search for multiple patterns
This command will search for both “fatal” and “error” in syslog.txt.
Read patterns from a file:
grep -f myparameters.txt syslog.txt
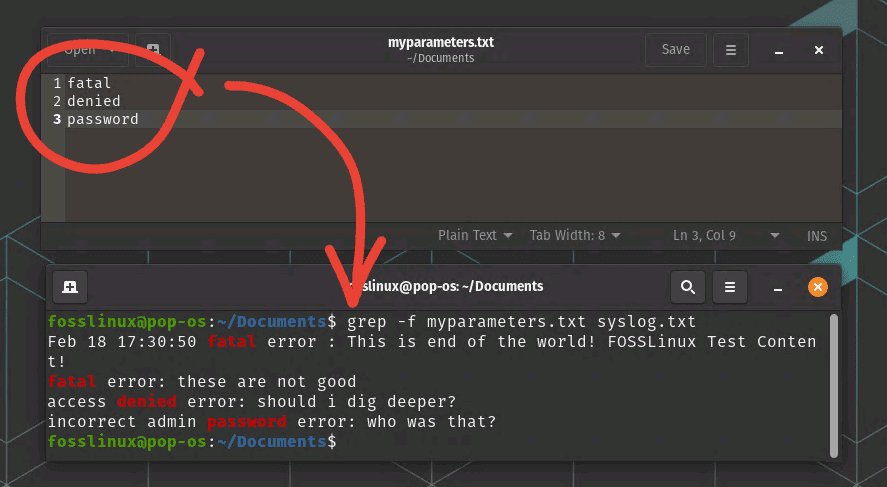
grep – Read patterns from a file
This command will search for all patterns listed in patterns.txt in file.txt.
Sed
Sed stands for Stream Editor. It is a command-line tool that can be used to edit text files. Sed reads the input file line by line and performs the specified actions on each line.
Basic Syntax
The basic syntax of sed is as follows
sed [options] 'command' file
command is the sed command to execute.
file is the file you want to edit. If no file is provided, sed will read from standard input (stdin).
Examples
Let’s start with some basic examples:
Replace a string in a file:
sed 's/error/OK/g' syslog_2.txt
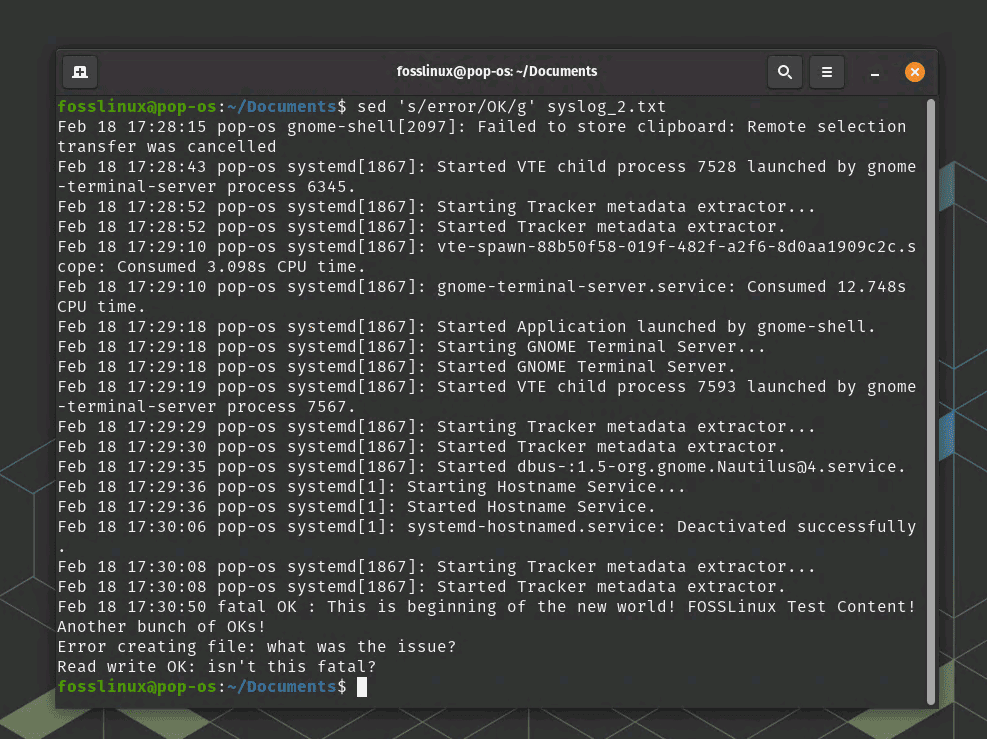
sed – replace a string in a file
This command will replace all occurrences of “error” with “OK” in the file syslog_2.txt and print the modified file to standard output.
Delete a line in a file:
sed '1d' syslog_2.txt
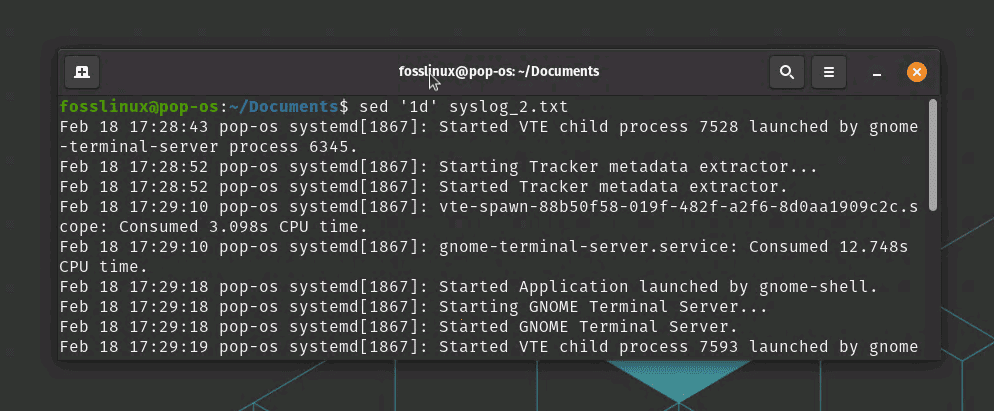
sed – delete a line in a file
This command will delete the first line of syslog_2.txt and print the modified file to standard output.
Insert a line in a file:
sed '1i\This is a new line' syslog_2.txt
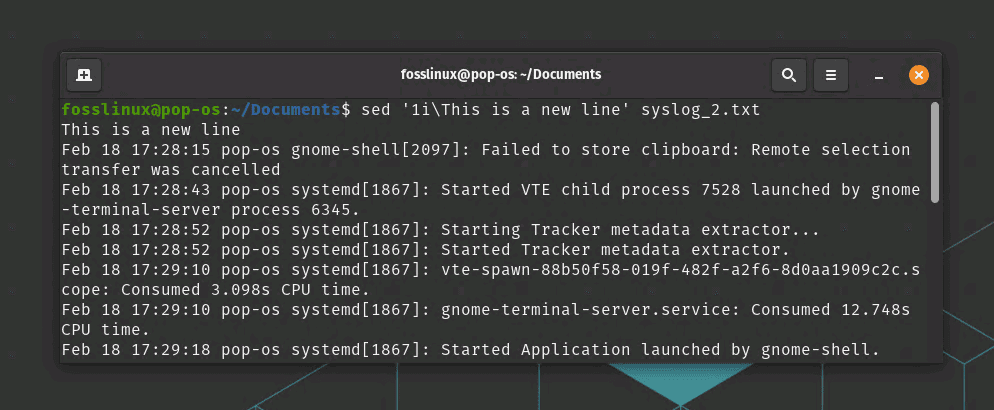
sed – insert a new line
This command will insert the text “This is a new line” at the beginning of syslog_2.txt and print the modified file to standard output.
Options
Sed has many options that can be used to customize its behavior. Here are some commonly used options:
- -i: Edit files in place.
- -e: Execute multiple commands.
- -n: Suppress automatic printing of lines.
- -r: Use extended regular expressions.
Examples
Edit files in place:
sed -i 's/old/new/g' file.txt
This command will replace all occurrences of “old” with “new” in file.txt and save the changes to the file.
Execute multiple commands:
sed -e 's/old/new/g' -e '1d' file.txt
This command will replace all occurrences of “old” with “new” and delete the first line of file.txt.
Suppress automatic printing of lines:
sed -n 's/old/new/p' file.txt
This command will search for “old” in file.txt and only print the lines that contain “old” after replacing it with “new”.
Use extended regular expressions:
sed -r 's/([0-9]+)-([0-9]+)-([0-9]+)/\3\/\2\/\1/' file.txt
This command will search for dates in the format “YYYY-MM-DD” in file.txt and replace them with the format “DD/MM/YYYY”.
Conclusion
Grep and sed are powerful command-line tools that can be used to search and manipulate text in a Unix/Linux environment. Grep can be used to search for patterns in a file or input, while sed can be used to edit text files. Both tools use regular expressions to match patterns and offer many options to customize their behavior. Learning to use grep and sed effectively can save time and make text processing tasks much easier.